Technical note
NVFP4 GGUF on Blackwell: what the benchmarks actually show
We shipped NVFP4 GGUF quants of three flagship multimodal models and benchmarked them against stock K-quants on an RTX 5090. Dense models win, MoE does not yet, and one number had to be re-run.

NVFP4 is NVIDIA’s 4-bit floating point format: an E2M1 mantissa with FP8 block scales over 16-element groups, executed natively by Blackwell tensor cores. Support landed in llama.cpp through PR #22196, and we wanted to know what it is actually worth for serving, measured rather than assumed.
We shipped three repos under LibertAIDAI: Qwen3.6-27B, Qwen3.6-35B-A3B and Gemma-4-31B-IT, each converted from NVIDIA ModelOpt-calibrated NVFP4 sources. Each repo carries three variants that share the calibrated NVFP4 feed-forward tensors and store the rest as BF16, Q8_0 or Q4_K_M, plus an F16 multimodal projector.
Methodology
The comparison that matters is apples-to-apples: our NVFP4-Q4_K_M variant against a stock Q4_K_M quant of the same model. Both files land in the same size class and use the same K-quant scheme everywhere except the feed-forward tensors, so the benchmark isolates one variable, which is whether the FFN matmul runs through the NVFP4 hardware path.
We ran single-stream tests with llama-bench (512-token prompt processing, 64-token generation, all layers on GPU, 3 runs averaged) and batched serving tests with llama-batched-bench (512 in, 128 out per request, at 1, 4, 8 and 16 parallel sequences, 16k context). Hardware was an RTX 5090 with 32 GB.
Dense models win, modestly and consistently
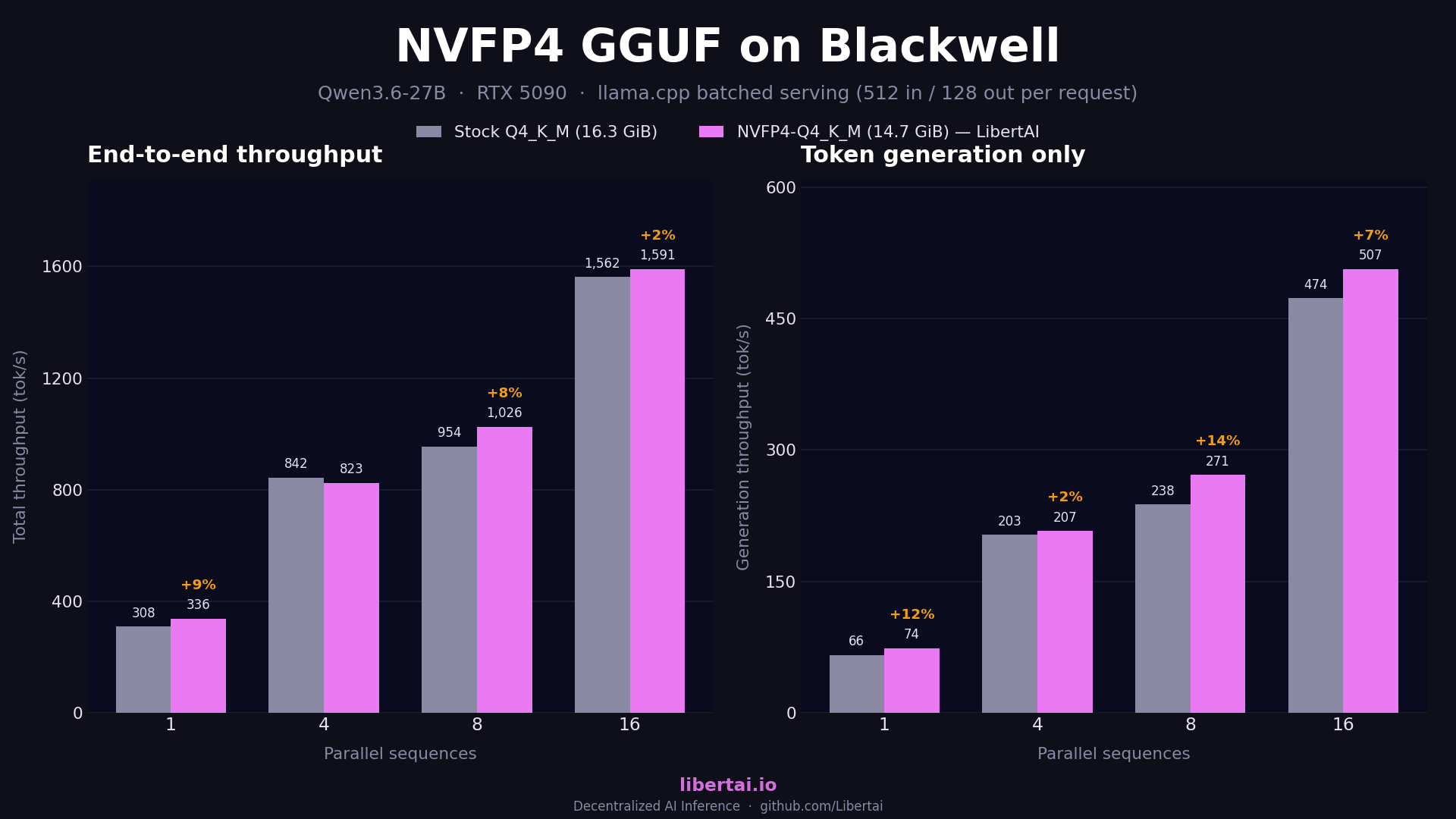
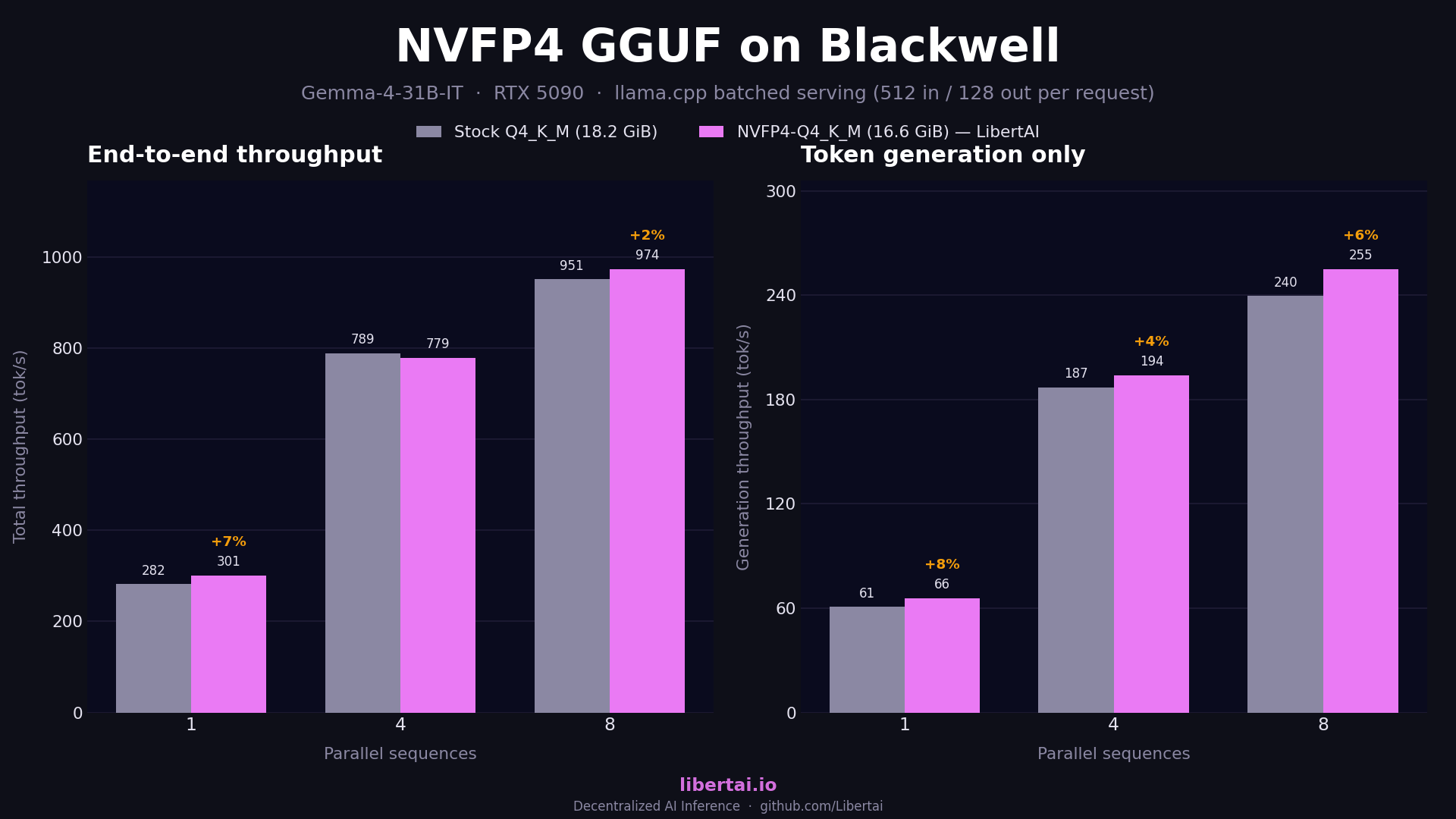
On the dense Qwen3.6-27B, NVFP4-Q4_K_M wins total serving throughput at every batch size we tested, with the largest gains at single stream and moderate batching, shrinking at high parallelism. The generation-only numbers, which are what serving latency feels like, show a consistent 5 to 14% gain across all batch sizes. Gemma-4-31B-IT behaves the same way with slightly smaller margins.
Where it does not win
Two results keep the story honest. First, the mixture-of-experts Qwen3.6-35B-A3B loses to stock Q4_K_M by roughly 5 to 10% across all batch sizes. llama.cpp’s Q4_K_M MoE path is heavily tuned and its NVFP4 expert dispatch is new, so we expect this to flip upstream eventually, and we will re-bench when it does. Second, the BF16 variants are dramatically slower than the small ones (378 versus 1,026 tokens per second for Qwen 27B at 8 parallel sequences), because the unquantized attention and embedding tensors make memory bandwidth the bottleneck regardless of how fast the FFN computes. They exist for source fidelity, and you should not serve from them.
The number we had to re-run
Our first batched bench of stock Qwen 27B at 4 parallel sequences returned 96 tokens per second of generation throughput, wildly below trend. The real value, confirmed by a clean re-run, is about 203; the original run had been contended by background download traffic on the same machine. The charts show the corrected data. The lesson is old but worth repeating: always re-bench a suspicious number before you publish it, especially one that flatters you.
What we claim and what we do not
The launch claim is that NVFP4 is competitive with K-quants on dense models, comes with NVIDIA ModelOpt calibration, and gives GGUF users format parity with vLLM, SGLang and TensorRT-LLM. We do not claim it is categorically faster than Q4_K_M, because our own MoE numbers say otherwise, and we have not yet run perplexity evaluations to back quality claims with data. Those are queued.