Technical note
NVFP4 GGUF performance on Blackwell: the consolidated numbers
Everything we have measured about NVFP4 GGUF serving across five models, three releases and one kernel generation, including the week the MoE result flipped in NVFP4's favor.

Since May we have published NVFP4 GGUF builds of five models under LibertAIDAI: Qwen3.6-27B, Qwen3.6-35B-A3B, Gemma-4-31B-IT, Gemma-4-12B-IT and, this week, Nex-N2-mini. Each release came with its own benchmarks, and the picture has changed as llama.cpp’s kernels matured. This note consolidates what we have measured so far, because the answer to “is NVFP4 faster” turned out to depend on the model family, the batch size, and the month you asked.
All numbers below come from an RTX 5090 (32 GB, Blackwell, sm_120). The format itself is NVIDIA’s 4-bit float, an E2M1 mantissa with FP8 block scales over 16-element groups, which Blackwell tensor cores execute natively. llama.cpp gained the CUDA path in PR #22196.
Method, and two pitfalls worth repeating
Every comparison is apples-to-apples: our NVFP4-Q4_K_M variant against a stock Q4_K_M quant of the same model. The two files land in the same size class and use the same K-quant scheme for everything except the feed-forward tensors, so the benchmark isolates one variable, namely whether the FFN matmul runs through the NVFP4 hardware path. We run single-stream tests with llama-bench and batched serving with llama-batched-bench at 1, 4, 8 and 16 parallel sequences, 512 tokens in and 128 out per request.
Two pitfalls have bitten us enough times to deserve their own paragraph. First, the toolchain: native sm_120 NVFP4 MMA requires CUDA 13.0, and a default nvcc from a 12.x toolkit will silently compile sm_86 binaries that run NVFP4 through PTX JIT, which works and quietly leaves performance on the table. Check the build with cuobjdump --list-elf before benchmarking anything. Second, anomalies: our very first stock baseline returned a generation number less than half the true value because background downloads were contending for the machine, and this week the stock prompt-processing number at single stream came out 50% low on a cold first run. Every outlier we re-ran moved toward the trend. We do not publish a number that surprised us without reproducing it warm.
Dense models: a consistent, modest win
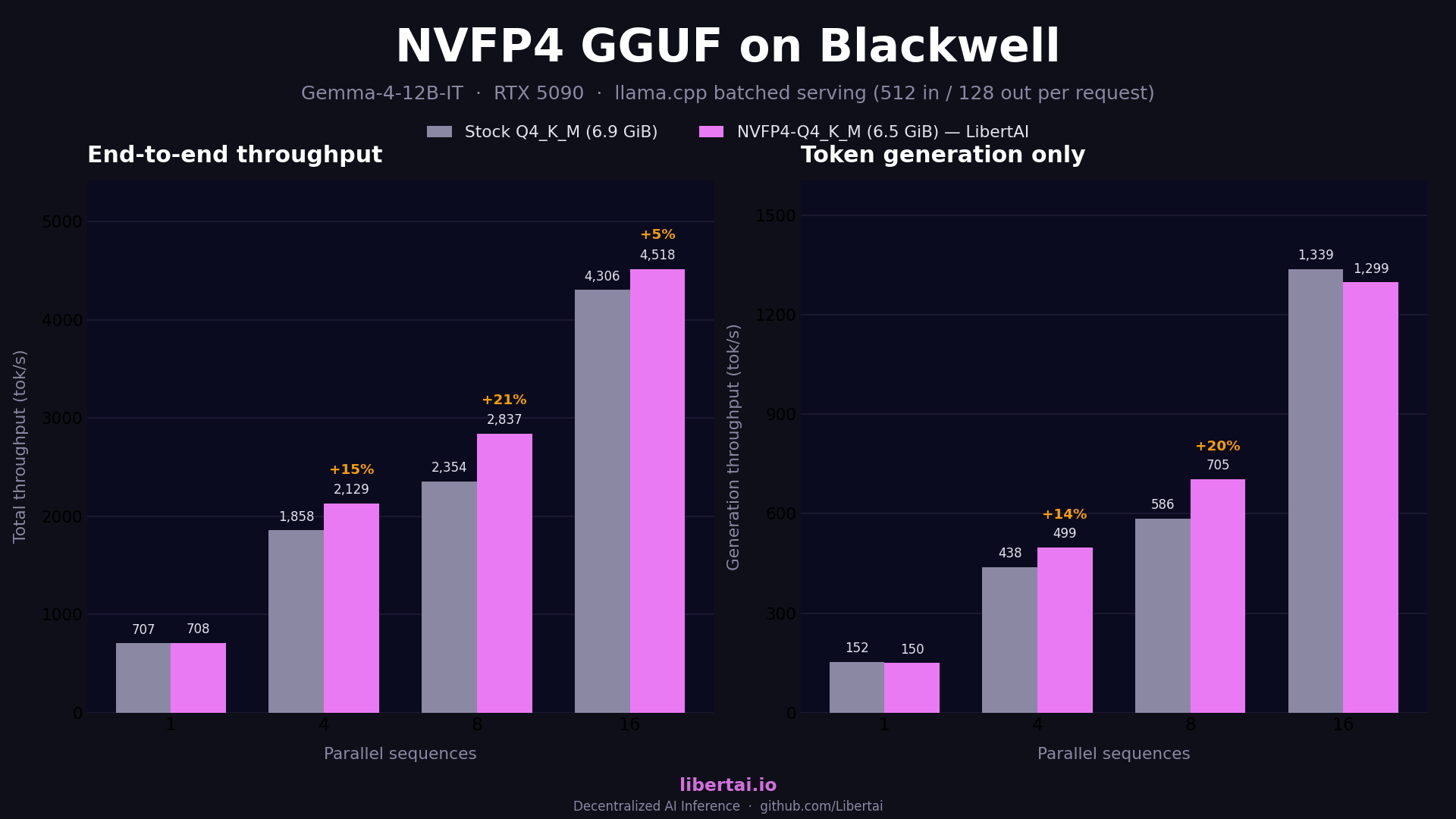
On dense models the result has been stable since May. Qwen3.6-27B gains 5 to 14% generation throughput across batch sizes, with end-to-end wins at every parallelism level we tested. Gemma-4-31B-IT behaves the same with slightly smaller margins, and Gemma-4-12B-IT, which we quantized ourselves with ModelOpt when no official checkpoint existed, ties stock at single stream and gains 15 and 21% total throughput at 4 and 8 parallel sequences before converging at 16, where attention and KV-cache traffic dominate and the FFN path stops mattering.
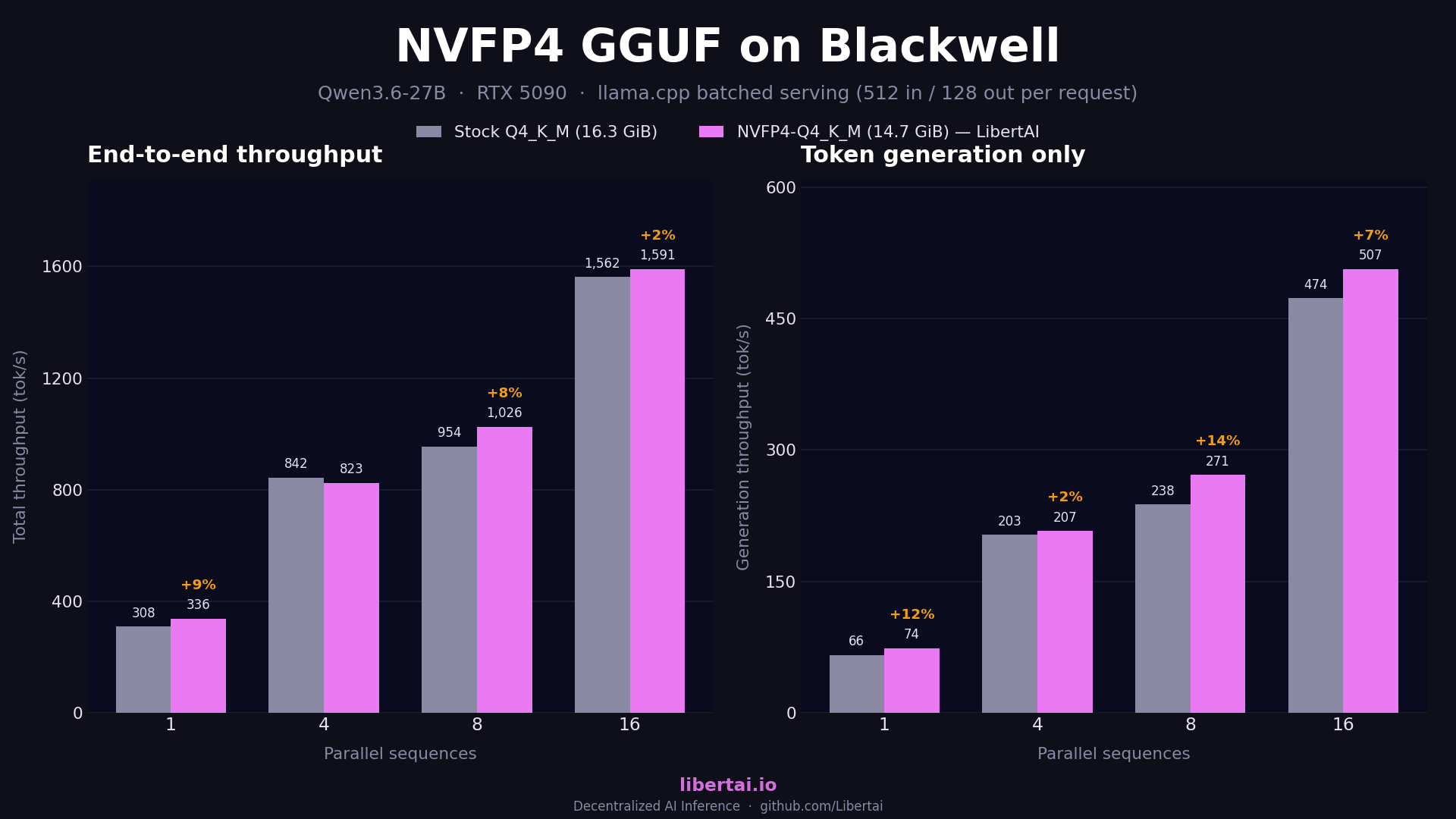
The variant ladder inside each repo tells the same bandwidth story from another angle. The smallest file is the fastest: NVFP4-Q4_K_M beats NVFP4-Q8_0, which beats NVFP4-BF16, and the BF16 carrier is dramatically slower (378 versus 1,026 tokens per second for Qwen 27B at 8 parallel sequences) because its unquantized attention and embedding tensors saturate memory bandwidth no matter how fast the experts compute. The BF16 file exists for source fidelity and as quantization input, not for serving.
Mixture-of-experts: the result that flipped
In May, the honest section of our launch writeup said that Qwen3.6-35B-A3B lost to stock Q4_K_M by 5 to 10% across all batch sizes, because llama.cpp’s K-quant MoE path was heavily tuned and the NVFP4 expert dispatch was new. We predicted the result would flip once upstream optimization landed, and committed to re-benching.
It flipped. This week we released Nex-N2-mini, a 35B-total, 3B-active MoE with 256 experts on the Qwen3.5-MoE architecture, and on llama.cpp build 85f99dca8 the NVFP4 build wins batched serving at every multi-stream batch size: 3% more total throughput at 4 parallel sequences, 5% at 8, 5% at 16, with prompt processing roughly 10% faster across the board. The NVFP4 file is also 1.5 GiB smaller (18.41 versus 19.91 GiB), which is KV-cache headroom at serving time.
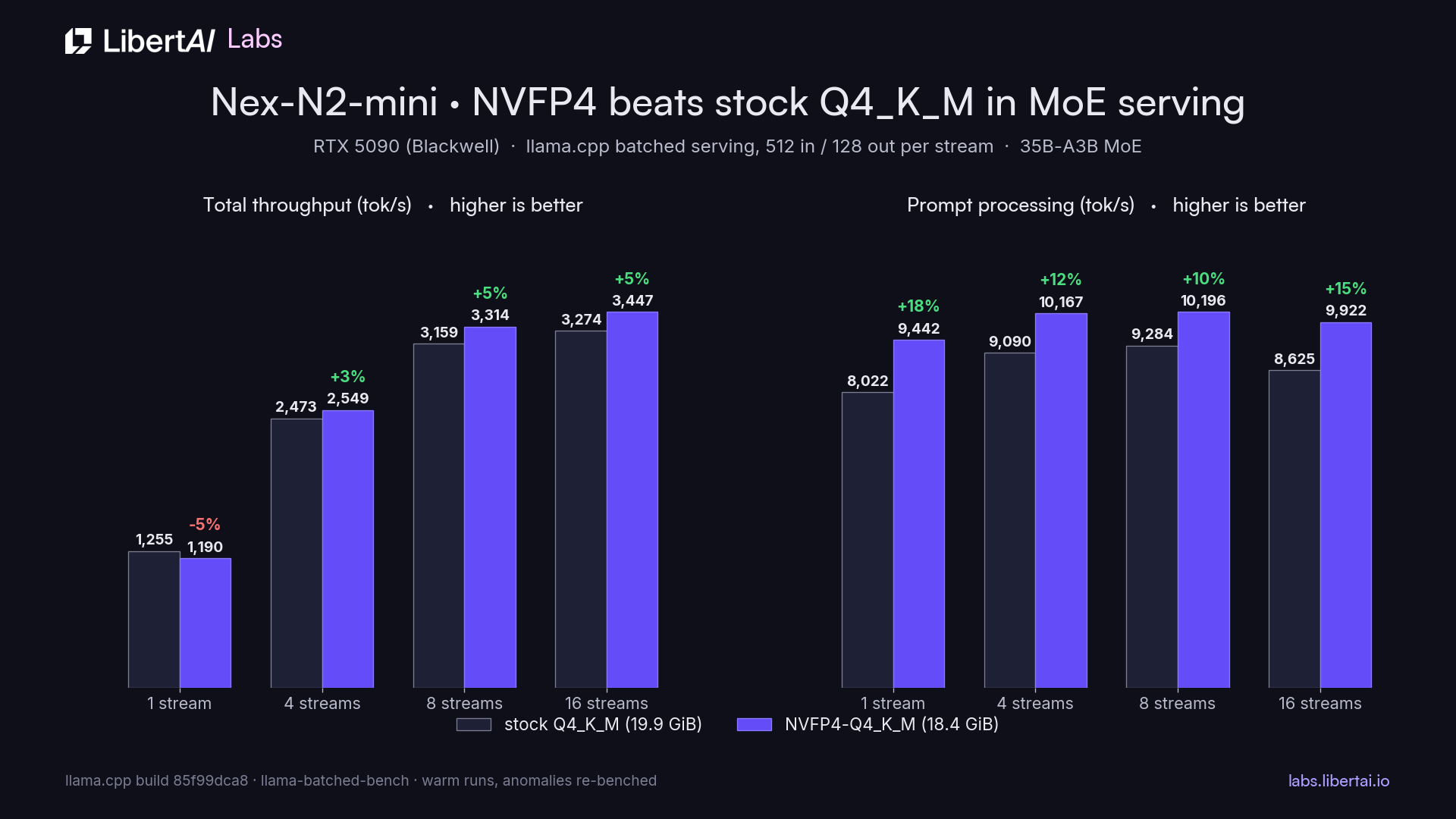
The caveat that keeps this honest: stock Q4_K_M still wins single-stream generation by about 5% (and by 13% in isolated llama-bench runs), so a single-user chat setup has no reason to switch. The win is in concurrent serving, which is where we run models anyway. We have not re-benched Qwen3.6-35B-A3B on the current build yet; its model card still carries the May numbers and we expect the same flip there.
A side observation from the same release: Nex-N2-mini’s hybrid linear attention keeps KV state on only 10 of 40 layers with 2 KV heads, so the full 256k context plus the vision projector fits a single 5090 in 27.6 GB, with 256k tokens of f16 KV cache costing about 5 GB. That is an architecture property rather than an NVFP4 one, but it compounds with the smaller weights into a serving configuration we did not expect to fit on one consumer card.

Multi-token prediction: dense wins again, MoE does not
The MTP follow-up release in late May showed the same family split as the base quants, for the same underlying reason. On the dense Qwen3.6-27B, the BF16 draft head lifts generation from 74.4 to 90.8 tokens per second in our production server configuration, a 22% gain at a 70% draft-accept rate. On the MoE, drafting costs more than verification saves, because the 3B-active base model is already so fast that the draft and verify overhead exceeds the value of accepted tokens: 27% slower at default settings, still 2% behind after tuning. The MoE MTP files are published for completeness and research, and the model cards lead with that framing rather than a speedup number. Details are in the MTP note.
What we recommend, and what is still open
For serving on Blackwell hardware, use the NVFP4-Q4_K_M variant: it is the smallest file in each repo, the fastest under concurrency on both dense and (now) MoE models, and it carries NVIDIA ModelOpt activation-aware calibration rather than round-to-nearest quantization. For single-user setups on a dense model the gain is real but small; on an MoE, stock K-quants remain marginally faster at single stream. On pre-Blackwell GPUs the files run through fallback kernels and offer no performance advantage, so there is no reason to prefer them there.
Two things remain open. We still have not run perplexity or downstream-task evaluations to put numbers behind the calibration quality argument, so we continue not to make quality claims beyond “calibrated versus RTN”. And the Qwen3.6-35B-A3B re-bench on current kernels is queued; when it lands we will update that model card the same way this note updates the story.