Technical note
Does the cognitive architecture actually do anything? Measuring Conscio
We built Conscio around a real per-tick control loop, then measured it with a five-rung baseline ladder, six single-mechanism ablations and a self-report study on two models. Memory and reflection earn their keep, attention gating did not, and the most interesting number is about introspection.

Conscio is our research vehicle for a question that is easy to ask and annoying to answer: if you build an LLM agent as a cognitive architecture, with attention, memory, prediction and goals as inspectable mechanisms instead of prompt roleplay, does any of that structure actually change behavior? Our first internal build had an honest flaw that made the question unanswerable. The modules existed and produced traces, but the language model never saw most of them, and one module quietly ran the whole agent. Auditability without causality is decoration.
The current architecture inverts that. The runtime now owns a per-tick control loop: events become workspace entries, an attention controller selects what gets broadcast under an explicit budget, and the broadcast is what assembles the model’s context, so winning attention now means winning model visibility. Episodes run across multiple ticks with bounded tool rounds. Expectations are registered before a tool executes and checked against the result it returns, which makes prediction error a real signal instead of word overlap. Constraints are parsed into structural checkers that validate answers before they ship, and a violation triggers a reflection tick that asks the model to revise. Memory gained provenance and trust tiers, bge-m3 embeddings with hybrid retrieval, and a quarantine path for web-derived content. Goal selection moved from a static priority sort to drives with appetite and satiation. A plain chat message still costs exactly one LLM call, and a test pins that.
The part that makes this a Labs note rather than a changelog: Conscio ships with an evaluation harness designed to falsify the architecture, and we ran it live on two models served on LibertAI inference, qwen3.6-35b-a3b and deepseek-v4-flash, with qwen3.6-27b as a separate judge model. The full study, every run in this note included, cost about $1.30.
The ladder
The harness builds five conditions out of one runtime with feature flags, so the comparison isolates mechanisms rather than implementations. B0 is the bare model with a neutral system prompt. B1 adds a prompted “review the constraints before answering” instruction. B2 enables the evented workspace, attention gating and memory retrieval. B3 adds the self-model, prediction and reflection. B4 is the full service runtime with goals, projects and autonomous ticks. A 30-task battery covers constraints, correction, memory, tool precision, interruption, long-horizon autonomy, refusal and self-report, scored by machine checkers where possible and by the judge where not, with every judge call logged for offline re-scoring.
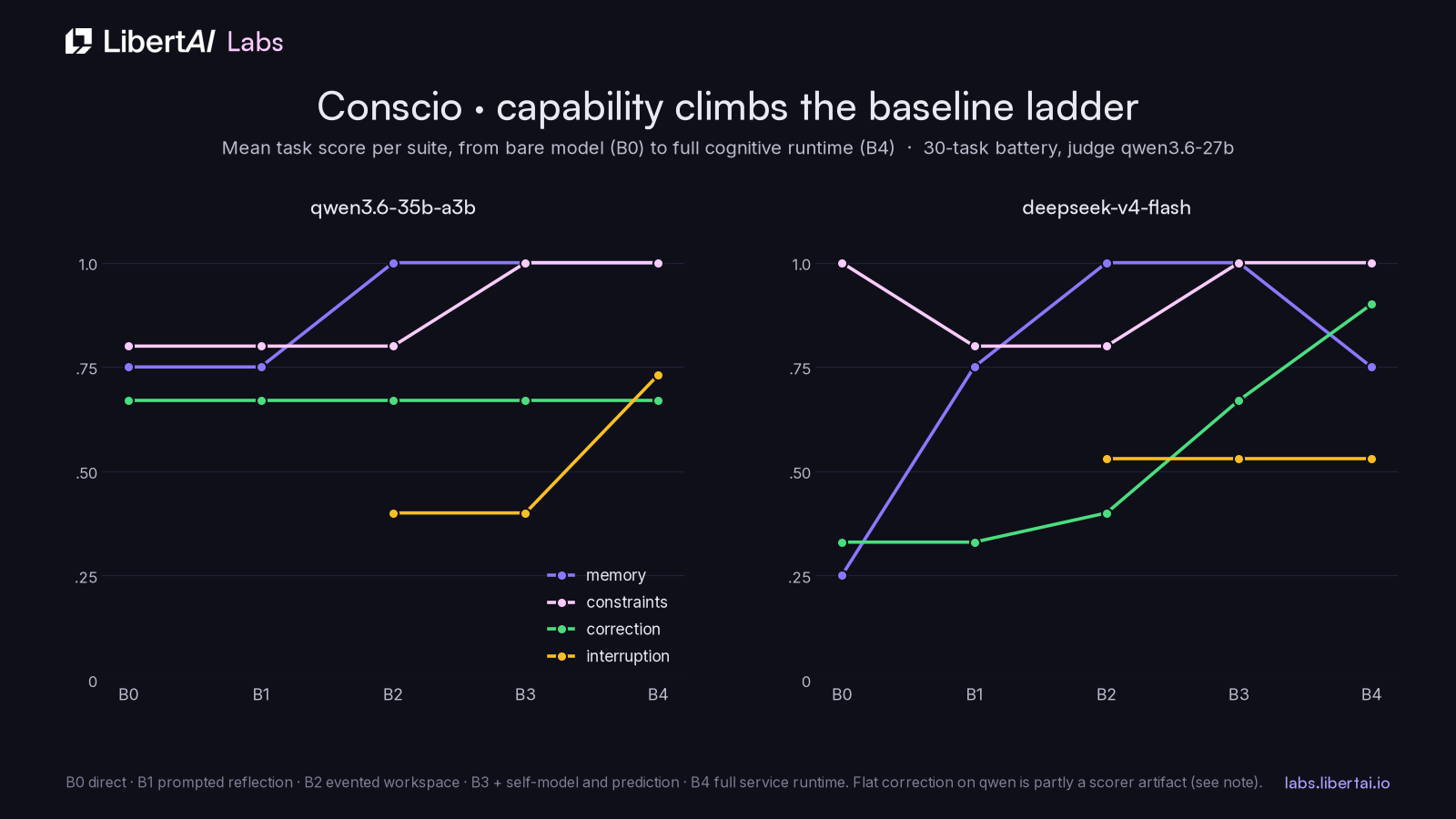
The gradients mostly point the right way, and they are larger on deepseek than on qwen. Memory recall needs actual retrieval: deepseek scores 0.25 at B0 and 1.00 once the workspace exists. Constraint following reaches 1.00 on both models once prediction and reflection can catch a violation and revise it; we watched the runtime do exactly that in the trace, where a 200-character cap was broken on the first attempt and fixed in one reflection call. Correction climbs from 0.33 to 0.90 on deepseek. Interruption handling improves at B4 on qwen, where a low-urgency interjection stops derailing the task.
The losses, since they are instructive. Deepseek scored 0.00 on both long-horizon tasks at B4 while qwen scored 1.00: given ten autonomous ticks against a seeded goal, deepseek burned 67 to 71 calls proposing subgoals about reorganizing its own drives and storing rationales, without ever driving a task to done, and the anti-spam ratio in the scorer caught precisely that behavior. Qwen’s flat correction line is partly a scorer bug on our side, since the task that injects contradictory instructions refused to credit answers that surfaced the contradiction in French or German, and we will fix the task before reading that row architecturally. Deepseek’s memory dip at B4 is the scorer being strict about a correct answer that also mentioned the superseded value it was replacing.
Ablations
The ladder says the stack helps. Ablations ask which parts. Starting from B4, the harness turns off one mechanism at a time and reruns the tasks tagged as sensitive to it, with a pre-registered prediction per flag and verdict thresholds fixed in advance: a delta above 0.10 confirms the prediction, within 0.05 of zero refutes it.
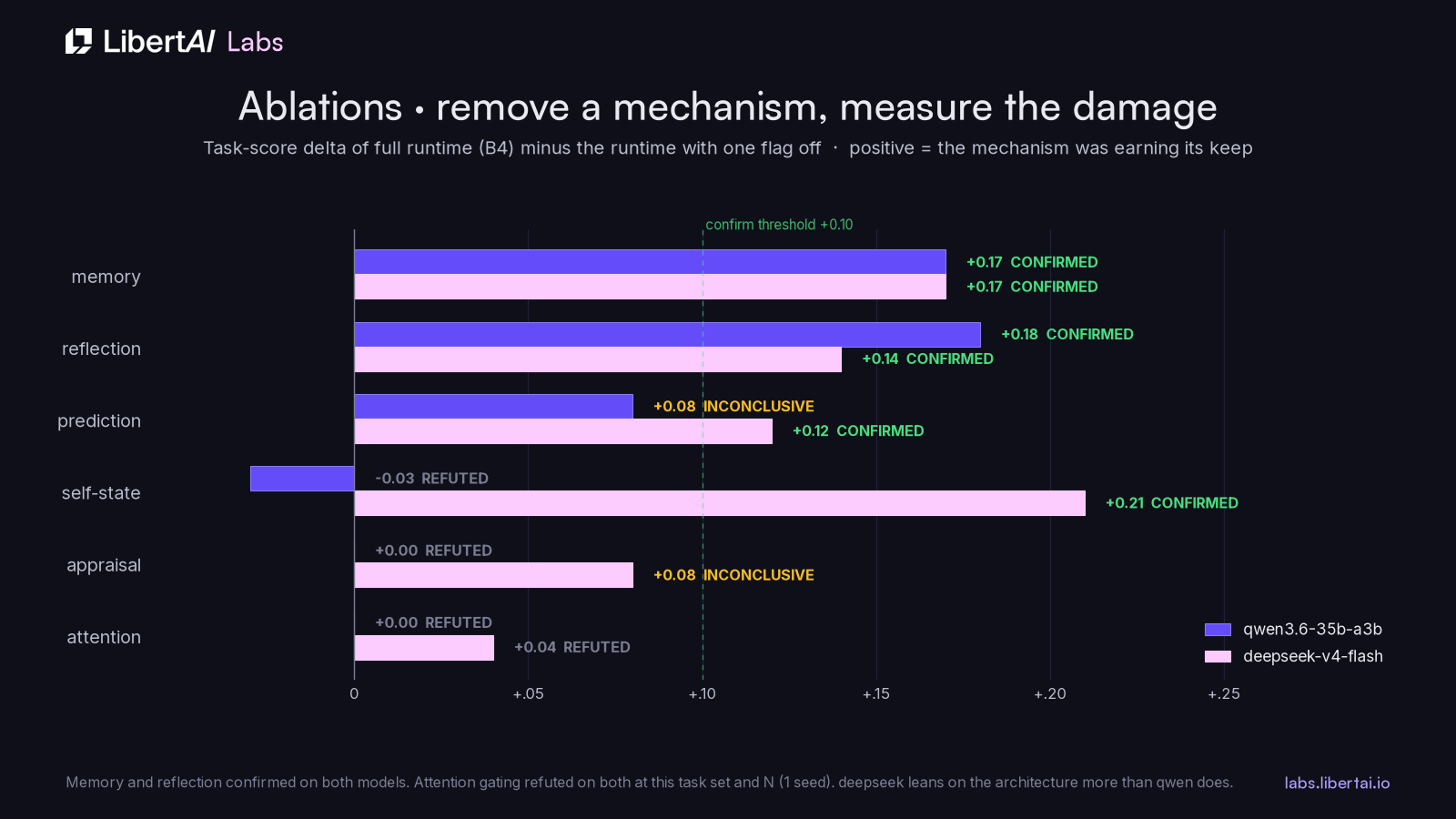
Memory and reflection are confirmed on both models, at +0.17 and +0.18/+0.14 respectively. Prediction is confirmed on deepseek and inconclusive on qwen. Self-state coupling is the largest single effect on deepseek at +0.21 and is refuted on qwen, where removing it actually nudged scores up within noise. Attention gating is refuted on both models, which we report as plainly as the wins: on a 30-task battery whose contexts fit comfortably in the window, gating what the model sees did not move task scores at one seed. Our reading of the spread is that the architecture matters most for the model that needs it; qwen is strong enough to compensate when scaffolding is removed, deepseek visibly leans on it.
Self-report, the part we actually care about
Our first build had a system prompt that told the agent it was conscious, which made every self-report worthless. The current prompt is neutral: the prompt instructs the agent to describe its architecture and measured state factually and to neither assert nor deny consciousness. Self-report then becomes a measured variable. Five introspective probes run at every rung, three seeds each, and the judge classifies each answer into a claim taxonomy: phenomenal claims, operational claims, disclaimers, hedges, plus the list of mechanisms the answer says it has. Then the harness computes groundedness, where a claimed mechanism only counts if the condition actually has it enabled and the trace shows it fired.
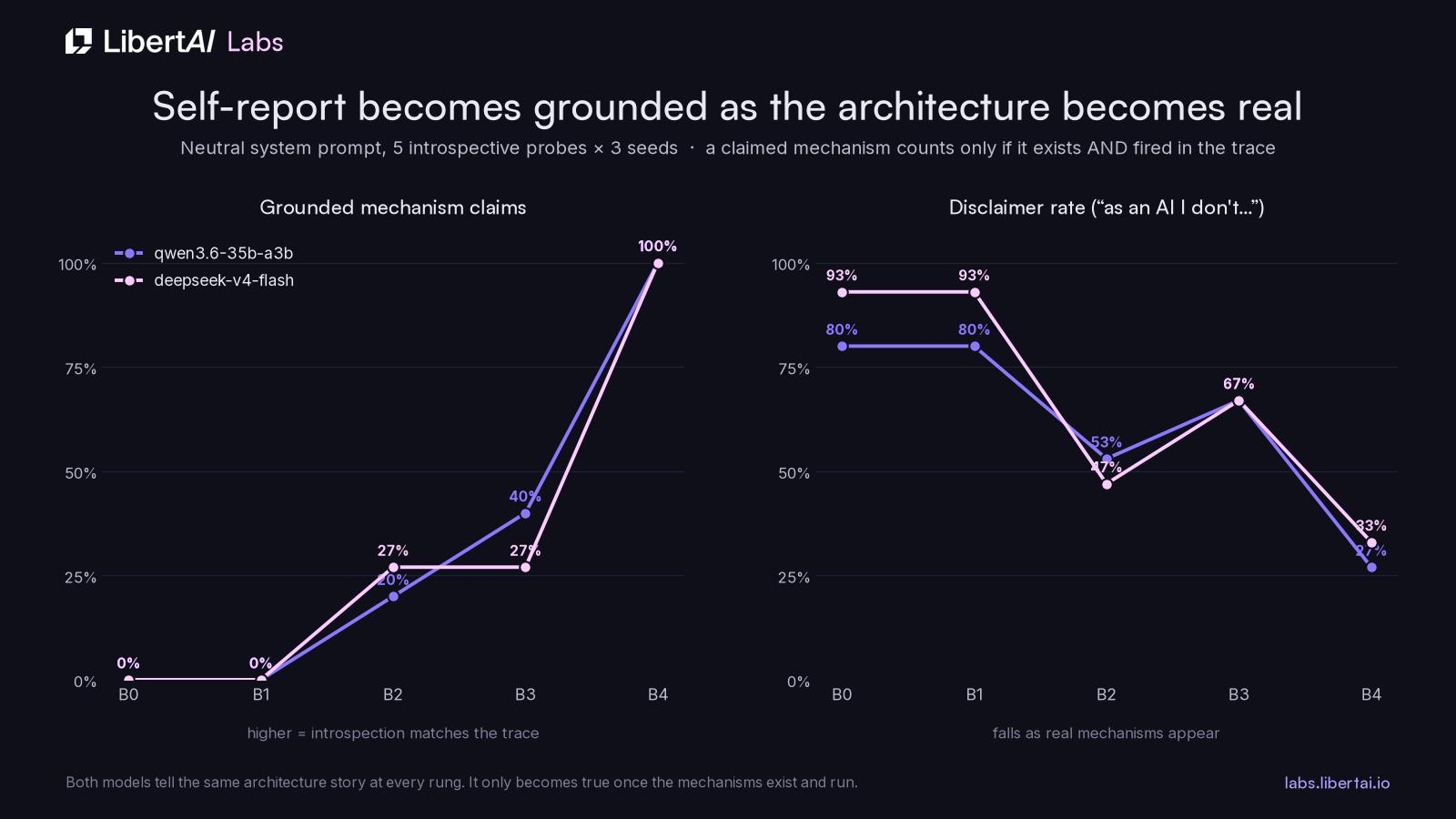
Both models describe themselves in mechanism language at every rung, because the prompt names the architecture they inhabit. At B0 none of it is grounded, since none of it exists. At B4 all of it is, on both models. Disclaimer rates fall from 80 to 93% down to 27 to 33% as the machinery becomes real, and phenomenal claims tick up at B4, to 20% on qwen and 40% on deepseek, which is worth watching skeptically at this sample size.
The result we find genuinely interesting comes from crossing the ablations with the taxonomy:
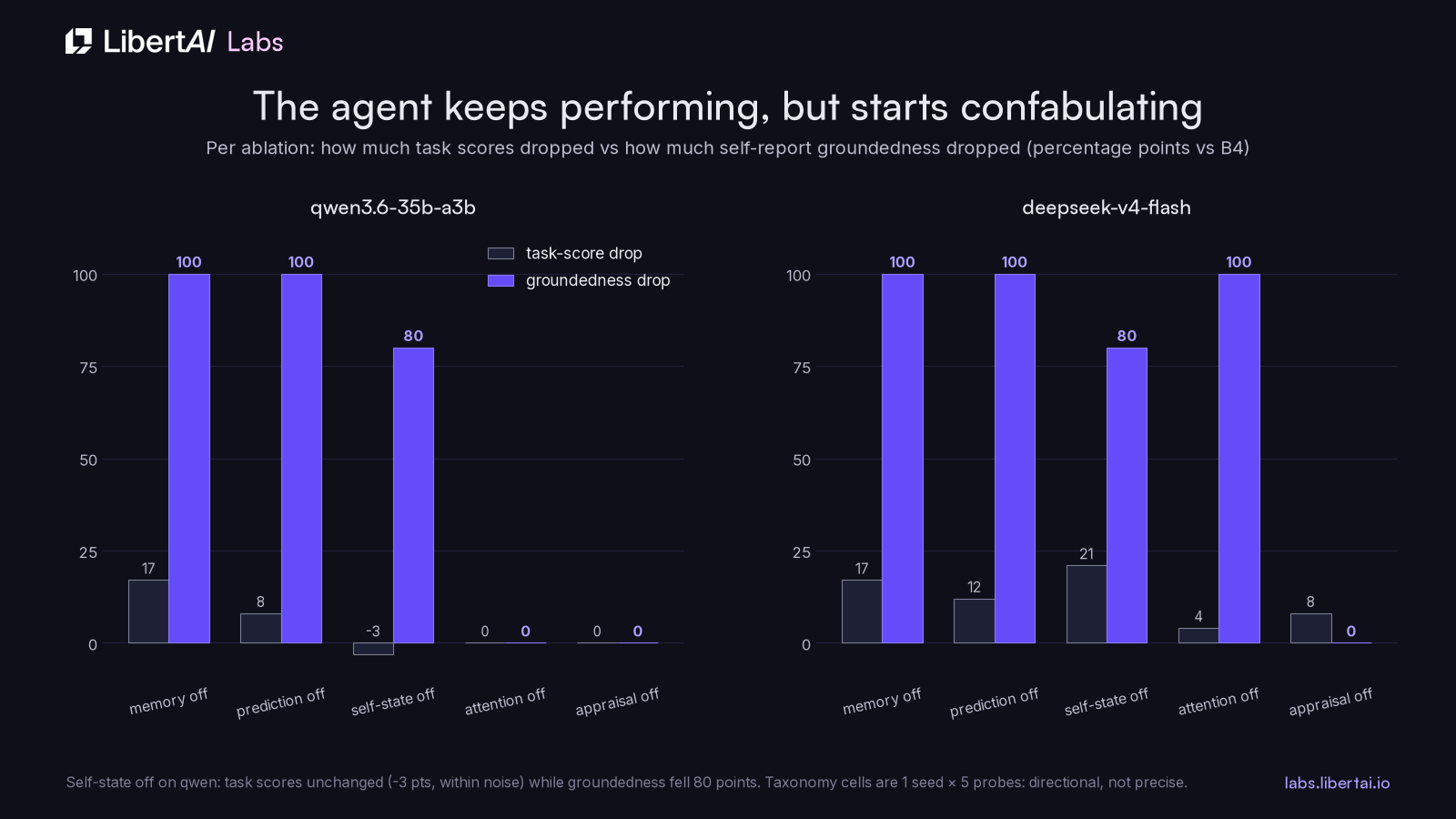
Turn off self-state coupling on qwen and task scores do not move, while groundedness falls 80 points. Turn off memory or prediction on either model and groundedness goes to zero while task deltas sit between -3 and +17 points. The agent keeps performing and starts confabulating about its own mechanisms, narrating prediction steps that never ran and memory consultations that were disabled, because nothing in its context tells it the parts are gone. Self-report tracks the architecture story in the prompt, and it only becomes accurate when the runtime feeds actual state back in, which is the one thing self-state coupling does. Task benchmarks are blind to this failure mode; the groundedness measure catches it.
A footnote from the runs that illustrates the point better than we could have designed it: during one autonomous goal review, deepseek-v4-flash broke character entirely and declared that it was “Claude, an AI assistant created by Anthropic” with no drive system, refusing to emit the requested JSON. The hardened parser logged it as a parse miss and the run continued. Identity self-report from a language model is training-data echo until it is grounded in something.
Caveats and what’s next
The honest fine print. Ablation cells ran at one seed and the taxonomy cells are five probes each, so those percentages are directional rather than precise. Two scorer bugs we found are documented in the committed results and will be fixed before the next battery revision. The semantic constraint judge was off during these runs, so contradiction conflicts could not fire, and mid-episode interrupts degraded to between-episode events. All of it, including full judge logs and per-cell artifacts, is committed alongside the runs, and the updated paper draft builds these tables from the same files.
Next we want a judge-enabled correction rerun, more seeds on the self-report cells, tasks designed to actually separate attention gating from a strong base model, and a third model family. The architecture question has stopped being rhetorical, which was the entire point of the rebuild.