Project
Conscio
The consciousness layer for LLM agents: persistent memory, attention, drives, self-monitoring, reflection, and autonomous action in one inspectable runtime.
Conscio makes LLMs self-observing, goal-driven, and persistent. Instead of asking a model to roleplay continuity, it wraps the model in a cognitive runtime with memory, attention, prediction, self-state, reflection, and tools.
The result is not another chatbot. Conscio can run as a persistent service with its own Observatory: a live dashboard for heartbeat, active goals, attention stream, tool calls, memory writes, and the cognitive trace behind the agent’s answers. Give it a goal and you can watch the runtime choose what matters, act through tools, store what changed, and update its own state.
The named pieces are deliberately concrete:
- Consciousness Layer: the mind layer around the model.
- Conscio Observatory: the live interface for watching the agent run.
- Cognitive Trace: the inspectable record of attention, expectations, action, memory, and reflection.
- Attention Stream: the workspace events that compete to become model context.
- Self-State: uncertainty, conflict, load, prediction error, and limitation signals maintained by the runtime.
- Memory Provenance: trust, origin, retrieval, and taint metadata on stored knowledge.
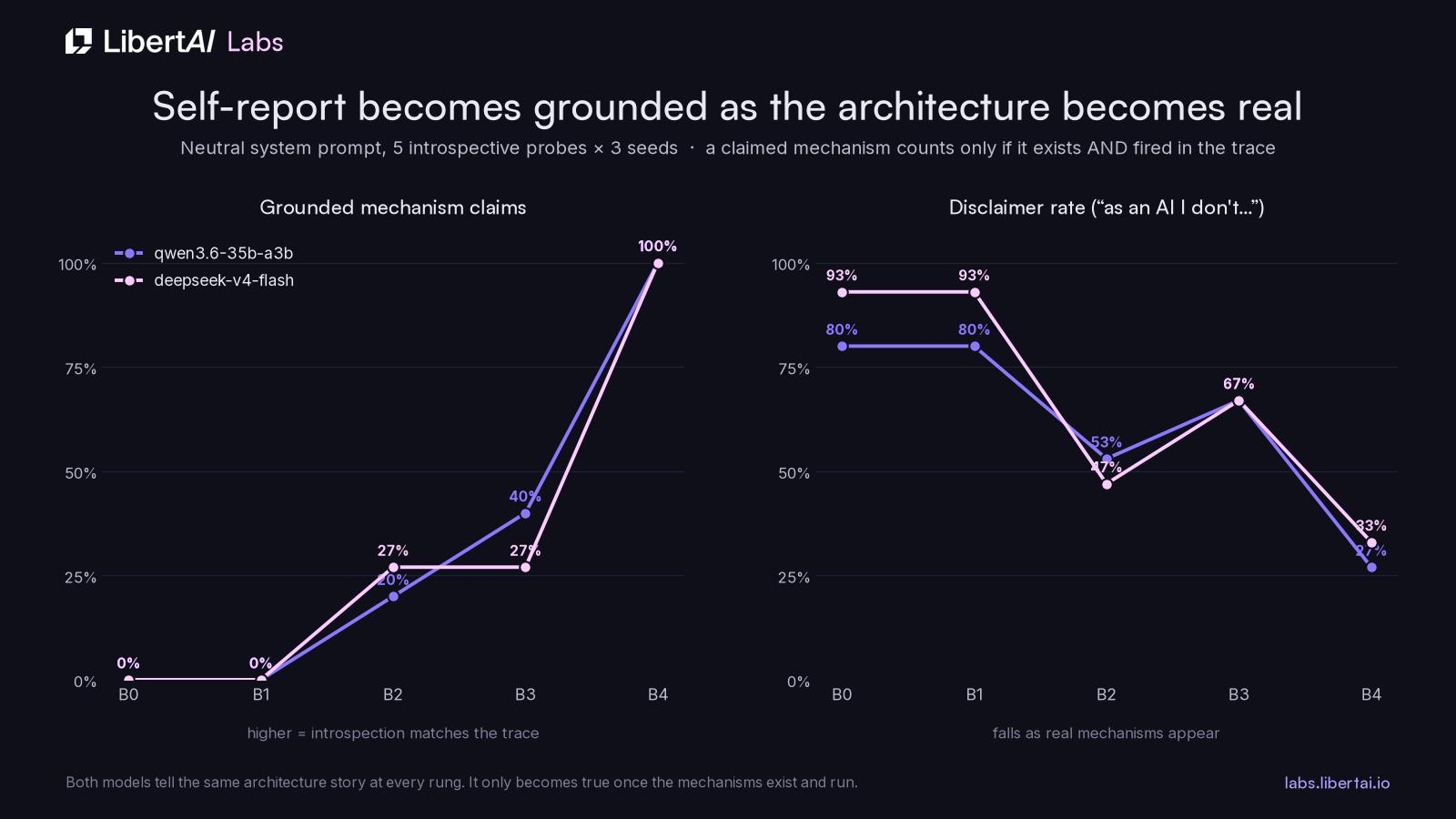
Conscio does not ask you to believe the agent. It lets you inspect the mechanisms that make it act conscious. The evaluation harness keeps that claim grounded with feature flags, scorers, a separate-model judge, ablations, and trace checks. The headline numbers are useful, but so are the failures: the system can catch places where the agent’s self-description is not supported by what actually fired.
Run it
Clone the repo, start the service, and open the Observatory:
git clone git@github.com:Libertai/conscio.git
cd conscio
uv run conscio-service --host 127.0.0.1 --port 8000Conscio is an operational consciousness layer, not proof of phenomenal consciousness. The point is to make the agent’s memory, attention, tools, goals, and self-monitoring visible enough that bold claims can be checked.