Project
NVFP4 model releases
GGUF and safetensors builds of flagship open models with calibrated NVFP4 tensors, benchmarked honestly against stock K-quants on Blackwell hardware.
NVFP4 is NVIDIA’s 4-bit floating point format. Blackwell GPUs execute NVFP4 matrix multiplication directly in their tensor cores, and llama.cpp gained support for the format in 2026. We publish GGUF builds that preserve the calibrated NVFP4 feed-forward tensors from NVIDIA ModelOpt sources and quantize the remaining weights to Q8_0 or Q4_K_M, plus safetensors builds for vLLM, SGLang and TensorRT-LLM.
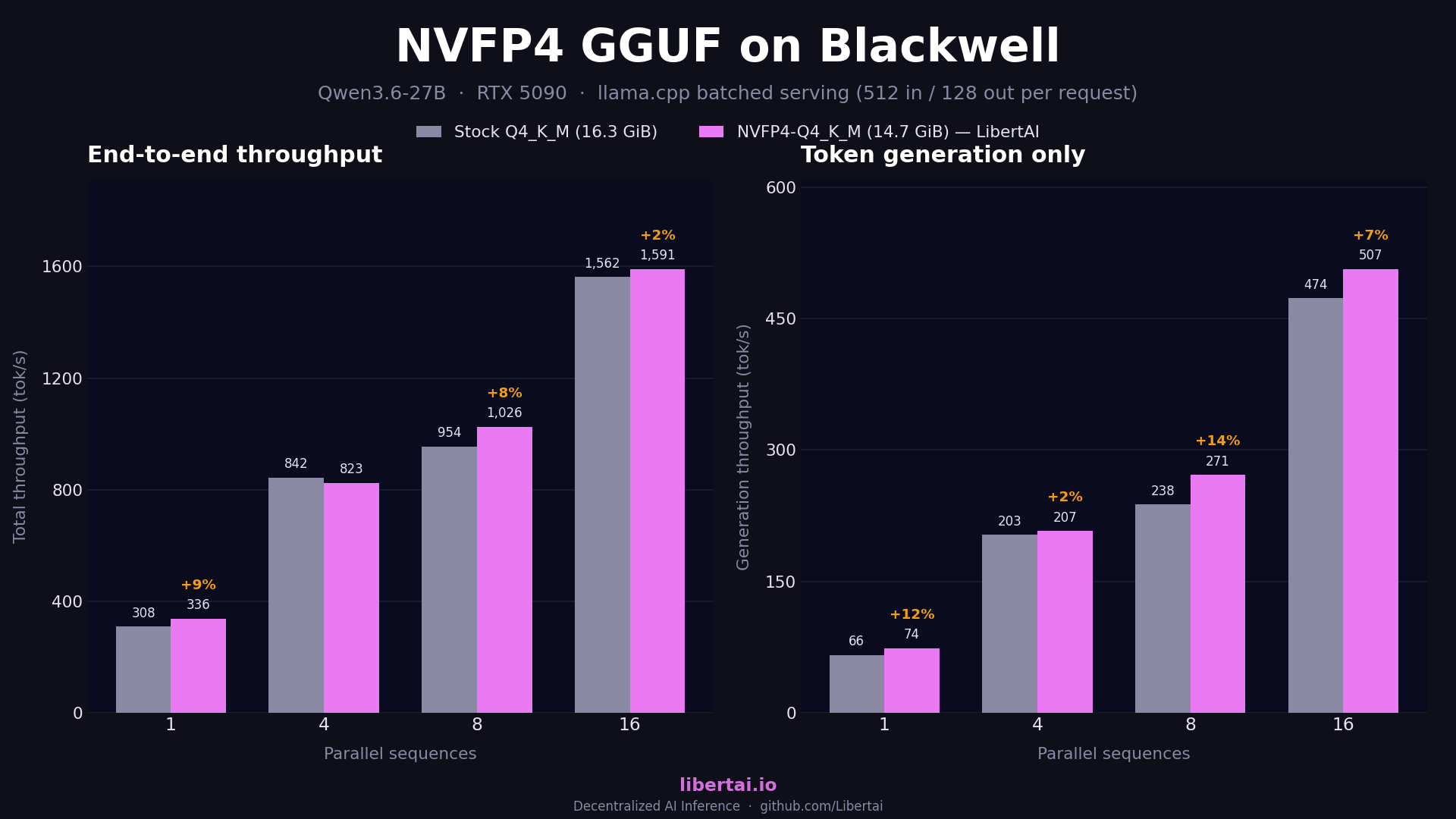
The claim we make is deliberately modest. On dense models, our NVFP4 builds match stock K-quants on end-to-end throughput and gain 5 to 14% on generation throughput on an RTX 5090. On mixture-of-experts models the heavily tuned stock kernels won until June 2026, when upstream optimization flipped the result: our Nex-N2-mini NVFP4 build now wins batched serving by 3 to 5% while stock keeps a small single-stream edge, and the model cards say both. The consolidated numbers across all five models are in the performance writeup, and the original methodology, including the benchmark number we had to correct, is in the launch writeup.
Releases
Download counts are from June 2026.
| Repo | What it is | Downloads |
|---|---|---|
| Qwen3.6-27B-NVFP4-GGUF | Dense 27B multimodal, NVFP4 FFN | 5,384 |
| Qwen3.6-27B-W4A16-G128 | GPTQ W4A16 for vLLM | 5,067 |
| Qwen3.6-35B-A3B-NVFP4-GGUF | MoE 35B (3B active), NVFP4 experts | 3,622 |
| Qwen3.6-27B-NVFP4-MTP-GGUF | 27B with multi-token-prediction draft head | 3,311 |
| Qwen3.6-35B-A3B-NVFP4-MTP-GGUF | MoE 35B with MTP draft head | 2,216 |
| Gemma-4-12B-IT-NVFP4-GGUF | Dense 12B | 1,790 |
| Gemma-4-31B-IT-NVFP4-GGUF | Dense 31B multimodal | 1,587 |
| Gemma-4-12B-IT-NVFP4 | Safetensors for vLLM and TensorRT-LLM | 1,322 |
| Nex-N2-mini-NVFP4-GGUF | MoE 35B (3B active), NVFP4 experts, fixed chat template | new |
| Nex-N2-mini-GGUF | Imatrix K-quants with the fixed chat template, any GPU | new |
What is in each GGUF repo
Every NVFP4 GGUF repo follows the same layout. There are three variants that share the calibrated NVFP4 feed-forward tensors and differ in how the remaining weights are stored: BF16 for maximum source fidelity, Q8_0, and Q4_K_M, which is the variant we recommend for serving. Multimodal models additionally ship an F16 projector for vision input, extracted from the official BF16 source.
The interesting property of the Q4_K_M variant is that it lands in the same file-size class as a stock Q4_K_M quant. Benchmarking the two against each other isolates exactly one difference: whether the feed-forward matmul runs through the NVFP4 hardware path or the K-quant path.